Revolutionizing Video Understanding: Introducing Storm Model

- Authors
- Published on
- Published on
In this riveting episode, the AI Coffee Break team delves into the shortcomings of current video language models, presenting the groundbreaking Storm model as the solution. Storm revolutionizes video understanding by intelligently compressing video sequences, enhancing the model's reasoning capabilities. By incorporating Mamba layers that scan the entire video sequence, Storm enriches tokens with global context, significantly reducing the number of tokens passed to the language model. This innovative approach not only streamlines the process but also improves the model's performance, outshining existing open-source models and even surpassing GPT4 on challenging video benchmarks.
Storm's architecture, combining SIG lip, Mamba layers, and Quent2VL language model, undergoes meticulous training on diverse datasets to ensure optimal performance on long videos. The model's bidirectional Mamba layers provide each frame with a memory of past and future events, enabling efficient temporal downsampling to further condense the input sequence. Storm's success on benchmarks like MVBench and MLVU underscores its superior efficiency and accuracy, setting a new standard in video understanding technology. By reducing redundant information and focusing on essential details, Storm not only boosts performance but also accelerates inference time, making real-time video analysis a tangible reality for various applications.
The AI Coffee Break team's in-depth exploration of Storm's capabilities reveals a transformative breakthrough in the field of video language models. Storm's ability to distill video sequences into concise yet informative tokens showcases a paradigm shift in how AI processes visual data. With its impressive performance on challenging benchmarks and significant efficiency gains, Storm paves the way for advanced applications in live stream analysis, lecture summarization, video editing assistance, and intelligent robotics. The future of video understanding looks brighter than ever, thanks to Storm's innovative approach and remarkable results in enhancing both accuracy and scalability in processing extensive video data.

Image copyright Youtube

Image copyright Youtube

Image copyright Youtube
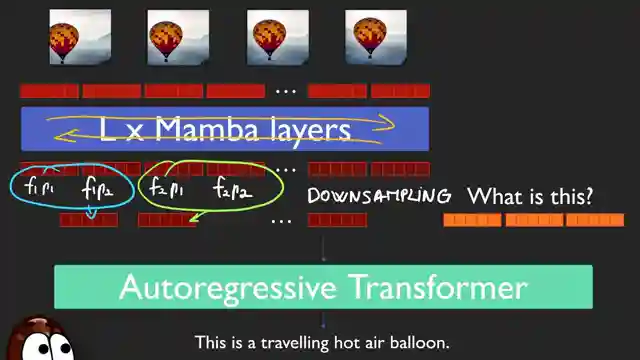
Image copyright Youtube
Watch Token-Efficient Long Video Understanding for Multimodal LLMs | Paper explained on Youtube
Viewer Reactions for Token-Efficient Long Video Understanding for Multimodal LLMs | Paper explained
Siglip on each frame does not see which objects are moving in the video
The Mamba layers learning which data is more redundant
Concerns about distortion of human perception with the technology
Request for advice on a Vision language model for a virtual human project
Suggestion to check if two frames have a 90% value match to decrease the number of frames that need to be summarized
Related Articles
Revolutionizing Video Understanding: Introducing Storm Model
Discover Storm, a groundbreaking video language model revolutionizing video understanding by compressing sequences for improved reasoning. Storm outperforms existing models on benchmarks, enhancing efficiency and accuracy in real-time applications.

Revolutionizing Large Language Model Training with FP4 Quantization
Discover how training large language models at ultra-low precision using FP4 quantization revolutionizes efficiency and performance, challenging traditional training methods. Learn about outlier clamping, gradient estimation, and the potential for FP4 to reshape the future of large-scale model training.

Revolutionizing AI Reasoning Models: The Power of a Thousand Examples
Discover how a groundbreaking paper revolutionizes AI reasoning models, showing that just a thousand examples can boost performance significantly. Test time tricks and distillation techniques make high-performance models accessible, but at a cost. Explore the trade-offs between accuracy and computational efficiency.
Revolutionizing Model Interpretability: Introducing CC-SHAP for LLM Self-Consistency
Discover the innovative CC-SHAP score introduced by AI Coffee Break with Letitia for evaluating self-consistency in natural language explanations by LLMs. This continuous measure offers a deeper insight into model behavior, revolutionizing interpretability testing in the field.