Running DeepSeek R1 Locally: Hardware, Costs, and Optimization

- Authors
- Published on
- Published on
In this riveting video by Aladdin Persson, we delve into the world of running DeepSeek R1 locally, a game-changer for LLMs. The sheer power of this 675 billion parameter model with 8-bit quantization is enough to make any tech enthusiast weak at the knees. But hold on to your hats, folks, because the cost of this cutting-edge setup is no mere pocket change - coming in at a cool 6K. Matthew Carrian, a Hugging Face engineer, takes us on a wild ride through the hardware and software setup required to unleash the full potential of DeepSeek R1.
The heart of this operation lies in the motherboard, boasting a whopping 24 DDR5 RAM slots to accommodate the mammoth memory requirements of these models. With the need to load the entire model into RAM, this component is the unsung hero of the setup. And let's not forget the CPUs - not just one, but two slots for those beefy 95 90004 AMD series processors. But here's the kicker: you don't need the latest and greatest CPUs to avoid bottlenecks; older models like the 9,115 or 9,15 will do just fine and save you a pretty penny.
RAM, RAM, and more RAM - 24 sticks of 32GB each are essential for this operation, ringing in at around 3.4K. And here's the plot twist - no GPUs required! That's right, you can achieve state-of-the-art LM performance locally without relying on those flashy graphics cards. But don't get too comfortable, because the real challenge lies in optimizing the setup for maximum throughput. From BIOS settings to SSDs with Linux, every detail counts in the quest for speed. And when it comes to actual performance, a demo reveals a throughput of 6-8 tokens per second - not too shabby for reading tasks, but a far cry from the lightning-fast speeds we crave for real-time reasoning.

Image copyright Youtube
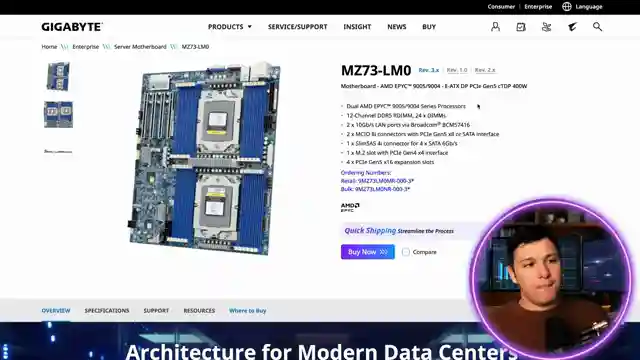
Image copyright Youtube
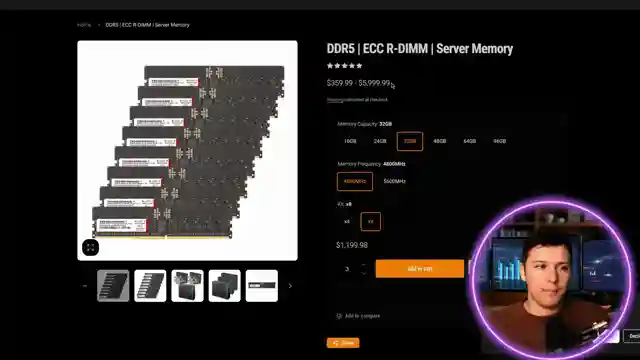
Image copyright Youtube
Image copyright Youtube
Watch How to run Deepseek-R1 locally for $6000 on Youtube
Viewer Reactions for How to run Deepseek-R1 locally for $6000
Multiple 3090 GPUs with software to spread the load and a motherboard to connect them all
Using a smaller model with 32 Billion parameters for VRAM efficiency
Consider getting a Mac mini with m4 max or m3 ultra
Waiting for the DGX Spark or DGX Station
Speculation about everyone running their own A.I. locally in the future
Related Articles

Revolutionizing Recommendations: 360 Brew's Game-Changing Decoder Model
Aladdin Persson explores a game-changing 150 billion parameter decoder-only model by the 360 Brew team at LinkedIn, revolutionizing personalized ranking and recommendation systems with superior performance and scalability.

Best Sleep Tracker: Whoop vs. Apple Watch - Data-Driven Insights
Discover the best sleep tracker as Andre Karpathy tests four devices over two months. Whoop reigns supreme, with Apple Watch ranking the lowest. Learn the importance of objective data in sleep tracking for optimal results.

Mastering Self-Supervised Learning: Fine-Tuning DNOV2 on Unlabeled Meme Data
Explore self-supervised learning with DNOV2 and unlabeled meme data in collaboration with Lightly Train. Fine-tune models effortlessly, generate embeddings, and compare results. Witness the power of self-supervised learning in meme template discovery and potential for innovative projects.

Unveiling Llama 4: AI Innovation and Performance Comparison
Explore the cutting-edge Llama 4 models in Aladdin Persson's latest video. Behemoth, Maverick, and Scout offer groundbreaking AI innovation with unique features and performance comparisons, setting new standards in the industry.