Revolutionizing AI: Quen's 32 Billion Parameter Model Dominates Coding and Math Benchmarks
- Authors
- Published on
- Published on
On 1littlecoder, we delve into the world of AI with a 32 billion parameter model from Quen that's turning heads in the tech realm. This David of a model is taking on Goliaths like the Deep Seek R1, a behemoth with 671 billion parameters, and holding its own in coding and math benchmarks. It's like watching a plucky underdog outshine the big shots in a high-stakes showdown.
What sets this model apart is its unique blend of reinforcement learning and traditional fine-tuning methods, a recipe for success in the competitive AI landscape. By using outcome-based rewards and accuracy verifiers for math problems, this model is honing its skills with precision. It's like a sharpshooter hitting the bullseye every time, raising the bar for AI performance.
But it doesn't stop there. The team behind this marvel has implemented a code execution server to ensure that the generated code meets predefined test cases, adding an extra layer of quality control. It's akin to a master craftsman meticulously inspecting every detail of their creation to perfection. And the results speak for themselves, with the model continuously improving in both coding and math through reinforcement learning.
This innovative approach not only enhances the model's performance but also focuses on developing its general capabilities, like instruction following, through a tailored reward model. It's like giving the model a crash course in human preferences and behavior, making it more versatile and adaptable. The team's dedication to pushing the boundaries of AI development is evident in their meticulous process and groundbreaking results, setting a new standard for innovation in the field.
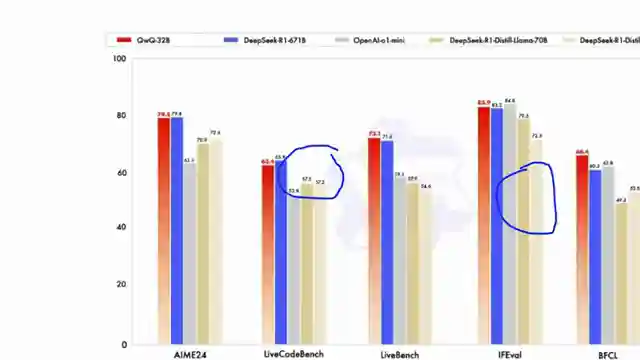
Image copyright Youtube
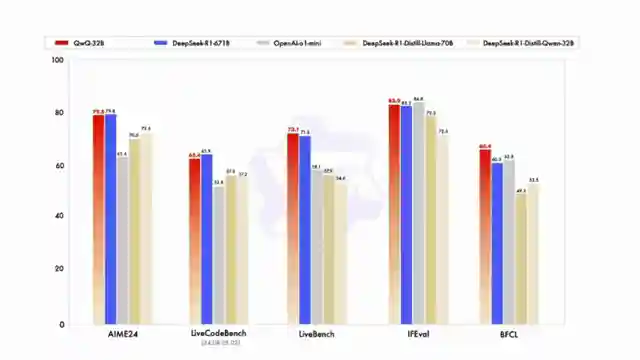
Image copyright Youtube
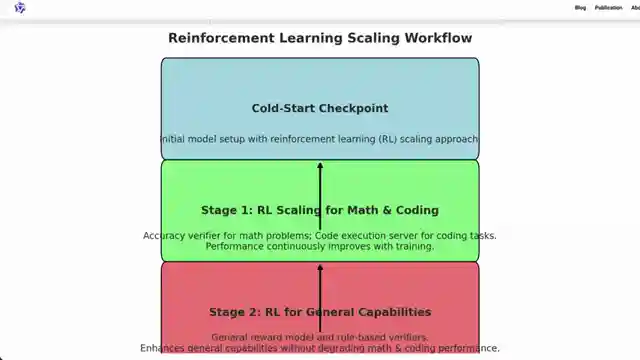
Image copyright Youtube

Image copyright Youtube
Watch Another Chinese 32B LLM matches Deepseek 671B??!!! on Youtube
Viewer Reactions for Another Chinese 32B LLM matches Deepseek 671B??!!!
QwQ-Max is yet to be released
Discussion on the performance of the models
Request for tests against full fp32/fp16 vs quantized versions
Speculation on VRAM requirements for running the model
Feedback on model testing and speed on slow hardware
Request for a Python function to print leap years
Support for the channel to reach 100k subs
Question about reasoning model with over 1 million tokens of context window
Mention of Chinese awareness on AI and reinforcement learning
Reference to Barto and Sutton winning the Turing Award
Related Articles

Revolutionizing Music Creation: Google's Magenta Real Time Model
Discover Magenta, a cutting-edge music generation model from Google deep mind. With 800 million parameters, Magenta offers real-time music creation on Google Collab TPU. Available on Hugging Face, this AI innovation is revolutionizing music production.

Nanits OCRS Model: Free Optical Character Recognition Tool Outshines Competition
Discover Nanits' OCRS model, a powerful optical character recognition tool fine-tuned from Quinn 2.5 VLM. This free model outshines Mistral AI's paid OCR API, excelling in latex equation recognition, image description, signature detection, and watermark extraction. Accessible via Google Collab, it offers seamless conversion of documents to markdown format. Experience the future of OCR technology with Nanits.

Revolutionizing Voice Technology: Chatterbox by Resemble EI
Resemble EI's Chatterbox, a half-billion parameter model licensed under MIT, excels in text-to-speech and voice cloning. Users can adjust parameters like pace and exaggeration for customized output. The model outperforms competitors, making it ideal for diverse voice applications. Subscribe to 1littlecoder for more insights.

Unlock Productivity: Google AI Studio's Branching Feature Revealed
Discover the hidden Google AI studio feature called branching on 1littlecoder. This revolutionary tool allows users to create different conversation timelines, boosting productivity and enabling flexible communication. Branching is a game-changer for saving time and enhancing learning experiences.