Optimizing LMS Models with Nvidia: Fine-Tuning for Enhanced Functionality

- Authors
- Published on
- Published on
In this exhilarating episode of James Briggs, we delve into the heart-pounding world of fine-tuning LMS models to become veritable agents of code mastery. Picture this: the roaring power of function calling capabilities propelling these models from mere text generators to code reviewers, PR writers, email checkers, and web search wizards. It's a thrilling transformation that sets the stage for a high-octane adventure in the realm of AI customization. Despite past shortcomings in function calling, the tides have turned, allowing for easy fine-tuning of LMS models to unleash their full potential in the agentic landscape.
Buckle up as we navigate through the treacherous terrain of heavy compute requirements, with Nvidia's Launchpad and H100 GPUs serving as our trusty companions on this adrenaline-fueled journey. The Nemo microservices from Nvidia emerge as our guiding lights, streamlining the fine-tuning process and paving the way for seamless production hosting of LMS models. Components like the customizer, evaluator, and Nvidia Nim stand as pillars of strength in this grand saga of model optimization and deployment.
As we gear up for the ultimate showdown, data sets are meticulously prepared and registered in the entity store, laying the foundation for the epic battle of model training. The customizer takes center stage, armed with the task of molding base models into formidable agents through rigorous training and parameter optimization. Deployment management emerges as the unsung hero, orchestrating the deployment of NIMs—powerful containers designed for GPU-accelerated tasks and model inference. In this adrenaline-pumping race against time, every component plays a crucial role in ensuring the seamless operation of the data preparation and customization pipeline.
Hold on tight as we hurtle towards the thrilling climax, where the data set from Salesforce emerges as the secret weapon in our arsenal, honed to perfection for training the legendary large action models. These models, revered for their prowess in function calling, epitomize the pinnacle of AI capability and stand ready to conquer new frontiers in the ever-evolving landscape of artificial intelligence. With the stage set and the engines revving, the stage is primed for a heart-stopping saga of innovation, customization, and the relentless pursuit of AI excellence.

Image copyright Youtube
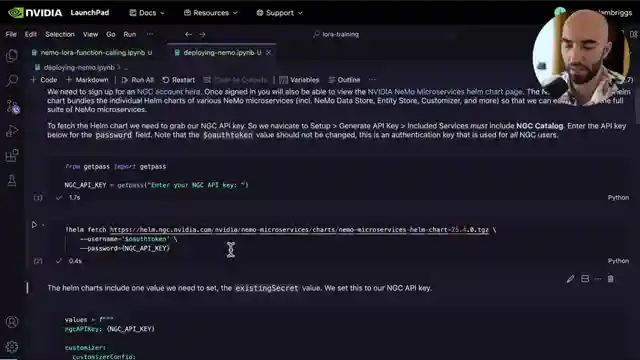
Image copyright Youtube
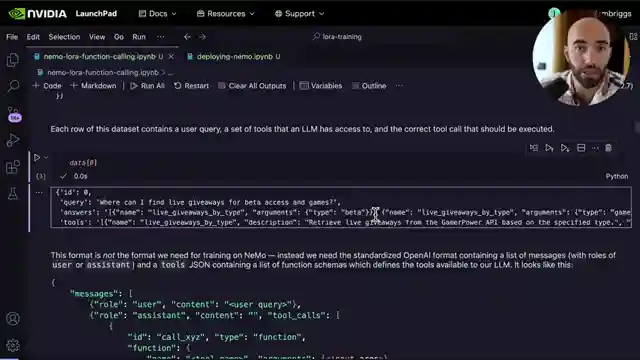
Image copyright Youtube
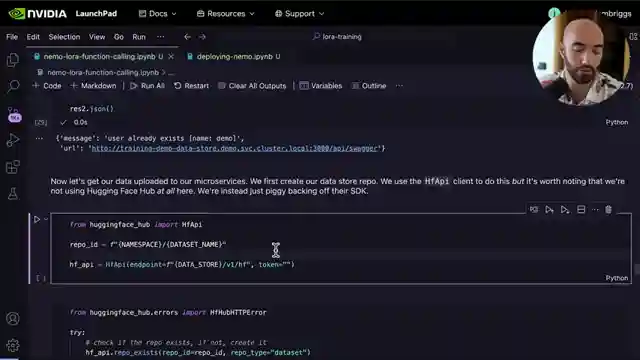
Image copyright Youtube
Watch LoRA Fine-tuning Tiny LLMs as Expert Agents on Youtube
Viewer Reactions for LoRA Fine-tuning Tiny LLMs as Expert Agents
Differences between creating a RAG database and using a model to access it
Other useful datasets available for training
NeMo Microservices
Deploying NeMo Code
LoRA Fine-tuning Code
Interest in using LoRa with llms
Interest in using LoRa with ComfyUi
Related Articles

Exploring AI Agents and Tools in Lang Chain: A Deep Dive
Lang Chain explores AI agents and tools, crucial for enhancing language models. The video showcases creating tools, agent construction, and parallel tool execution, offering insights into the intricate world of AI development.

Mastering Conversational Memory in Chatbots with Langchain 0.3
Langchain explores conversational memory in chatbots, covering core components and memory types like buffer and summary memory. They transition to a modern approach, "runnable with message history," ensuring seamless integration of chat history for enhanced conversational experiences.

Mastering AI Prompts: Lang Chain's Guide to Optimal Model Performance
Lang Chain explores the crucial role of prompts in AI models, guiding users through the process of structuring effective prompts and invoking models for optimal performance. The video also touches on future prompting for smaller models, enhancing adaptability and efficiency.

Enhancing AI Observability with Langmith and Linesmith
Langmith, part of Lang Chain, offers AI observability for LMS and agents. Linesmith simplifies setup, tracks activities, and provides valuable insights with minimal effort. Obtain an API key for access to tracing projects and detailed information. Enhance observability by making functions traceable and utilizing filtering options in Linesmith.