Exploring Cog VM: A Deep Dive into the 17 Billion Parameter Language Model

- Authors
- Published on
- Published on
In this riveting episode of Aladdin Persson's channel, we witness the relentless pursuit of streaming perfection. The team grapples with the limitations of their trusty MacBook when attempting to stream in glorious 4k resolution, only to face the dreaded lag. Despite the lack of concrete streaming plans, they boldly dive into the world of visual language models, particularly the groundbreaking Cog VM with a staggering 17 billion parameters. A comparison with the underwhelming Lava model sets the stage for an epic showdown of performance and prowess.
As the team delves into the intricate architecture of Cog VM, combining image and text features with vit MLP adapter and a pre-trained language model, the sheer complexity of this cutting-edge technology unfolds before their eyes. Drawing insights from the Lava paper, they uncover the model's innovative use of symbolic representations for image decoding, shedding light on the inner workings of these formidable language models. With plans to test Cog VM's mettle in tasks ranging from detail description to visual question answering, the team prepares to push the boundaries of AI capabilities.
Amidst the technical challenges of setting up Cog VM on a virtual machine and navigating the installation of NVIDIA drivers on Ubuntu, the team's determination shines through. Contemplating the potential of Big AGI for chat customization and pondering the benefits of renting workstations for model experimentation, they stand at the precipice of AI innovation. Through their relentless pursuit of excellence and unwavering curiosity, Aladdin Persson's team embodies the spirit of exploration and discovery in the ever-evolving landscape of artificial intelligence.

Image copyright Youtube
Image copyright Youtube
Image copyright Youtube
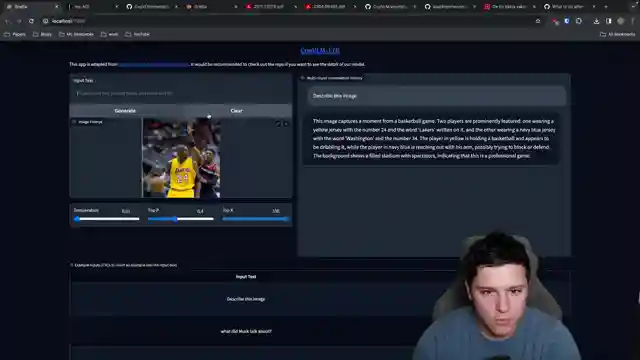
Image copyright Youtube
Watch CogVLM: The best open source Vision Language Model on Youtube
Viewer Reactions for CogVLM: The best open source Vision Language Model
Excitement for upcoming content
Request for more content on open source vision language models and tts models
Interest in fine-tuning tutorials
Concern about low likes compared to views
Positive feedback on the content
Use of model for auto captioning images
Request for in-depth tutorial on fine-tuning CogVLM
Request for tutorial on installing CogVLM on Mac
Comparison between CogVLM and LLaVa-NeXT
Inquiry about adding languages to CogVLM
Related Articles

Revolutionizing Recommendations: 360 Brew's Game-Changing Decoder Model
Aladdin Persson explores a game-changing 150 billion parameter decoder-only model by the 360 Brew team at LinkedIn, revolutionizing personalized ranking and recommendation systems with superior performance and scalability.

Best Sleep Tracker: Whoop vs. Apple Watch - Data-Driven Insights
Discover the best sleep tracker as Andre Karpathy tests four devices over two months. Whoop reigns supreme, with Apple Watch ranking the lowest. Learn the importance of objective data in sleep tracking for optimal results.

Mastering Self-Supervised Learning: Fine-Tuning DNOV2 on Unlabeled Meme Data
Explore self-supervised learning with DNOV2 and unlabeled meme data in collaboration with Lightly Train. Fine-tune models effortlessly, generate embeddings, and compare results. Witness the power of self-supervised learning in meme template discovery and potential for innovative projects.

Unveiling Llama 4: AI Innovation and Performance Comparison
Explore the cutting-edge Llama 4 models in Aladdin Persson's latest video. Behemoth, Maverick, and Scout offer groundbreaking AI innovation with unique features and performance comparisons, setting new standards in the industry.