Efficient Deployment of Open-Source Models on GPU Servers with NeuralNine

- Authors
- Published on
- Published on
In this exhilarating episode by NeuralNine, brace yourselves as we delve into the thrilling world of deploying open-source models on GPU servers using hugging face inference endpoints. It's like strapping yourself into a high-performance sports car, ready to unleash the full power of cutting-edge technology. By selecting your model, hardware, and connecting a payment method, you're on the fast track to running your model seamlessly through Python. It's like revving up the engine of a supercar, feeling the raw power at your fingertips.
As the adrenaline builds, viewers are taken on a heart-pounding journey through the process of setting up the environment and creating an inference client. The team recommends installing essential packages like paidantic, hugging face hub, lang chain openai, and python-.n for a smooth ride. It's like fine-tuning a high-performance engine, ensuring every component is optimized for peak performance. And for those seeking the ultimate speed, uv is the go-to choice for lightning-fast installation, like upgrading to a turbocharged engine for maximum acceleration.
With the stage set, users are guided on how to send messages to the model for lightning-quick responses. It's like navigating a high-speed race track, making split-second decisions to stay ahead of the competition. And for those craving precision and finesse, structured output is the key to unlocking the full potential of the model. By defining a schema with paidantic, users can ensure their responses are delivered in a specific, structured format. It's like fine-tuning a race car for optimal performance, ensuring every detail is meticulously crafted for maximum efficiency. So buckle up and get ready to experience the thrill of deploying open-source models like never before, with NeuralNine leading the way towards a high-octane future in technology.

Image copyright Youtube

Image copyright Youtube
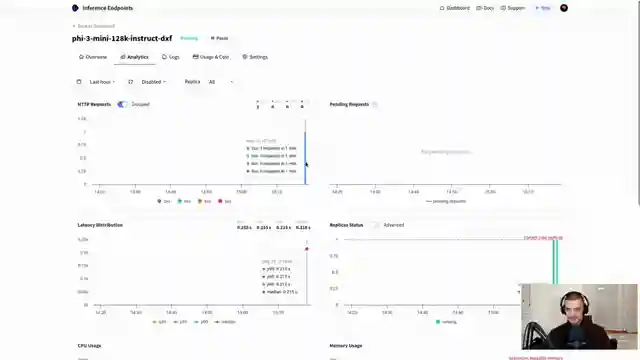
Image copyright Youtube
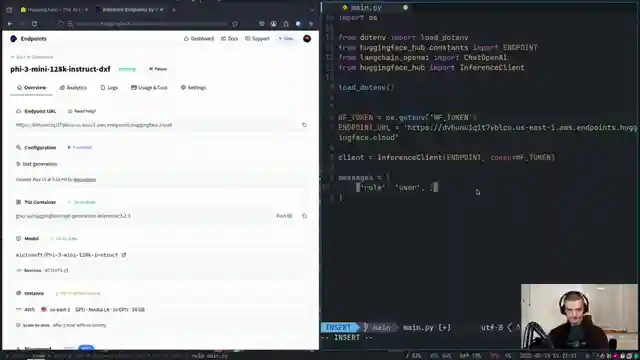
Image copyright Youtube
Watch The Easiest Way To Deploy Open Source Models... on Youtube
Viewer Reactions for The Easiest Way To Deploy Open Source Models...
Viewer finds the video more informative than 4 years of computer science
Discussion about using the code in Roo Code or OpenWEBUI
Viewer expressing gratitude for finding a video on the reverse topic
Viewer seeking guidance on using open source models for auto blogging, image generation, and video generation
Question about the adequacy of RTX 4060 for running image and video models
Comment on the lack of usage of UV
Related Articles
Building Stock Prediction Tool: PyTorch, Fast API, React & Warp Tutorial
NeuralNine constructs a stock prediction tool using PyTorch, Fast API, React, and Warp. The tutorial showcases training the model, building the backend, and deploying the application with Docker. Witness the power of AI in predicting stock prices with this comprehensive guide.

Exploring Arch Linux: Customization, Updates, and Troubleshooting Tips
NeuralNine explores the switch to Arch Linux for cutting-edge updates and customization, detailing the manual setup process, troubleshooting tips, and the benefits of the Arch User Repository.
Master Application Monitoring: Prometheus & Graphfana Tutorial
Learn to monitor applications professionally using Prometheus and Graphfana in Python with NeuralNine. This tutorial guides you through setting up a Flask app, tracking metrics, handling exceptions, and visualizing data. Dive into the world of application monitoring with this comprehensive guide.

Mastering Logistic Regression: Python Implementation for Precise Class Predictions
NeuralNine explores logistic regression, a classification algorithm revealing probabilities for class indices. From parameters to sigmoid functions, dive into the mathematical depths for accurate predictions in Python.