Unveiling Quen 2.5 Omni: Revolutionizing AI with Multimodal Capabilities

- Authors
- Published on
- Published on
Today, we delve into the world of AI with the new Quen 2.5 Omni model, a groundbreaking creation that allows for a multitude of inputs and outputs. This open-source marvel is a game-changer, offering a fully multimodal experience like never before. With the ability to process text, audio, video, and images, Quen's model opens up a world of possibilities for users looking to interact in a whole new way.
The Quen 2.5 Omni model shines in its voice and video chat capabilities, showcasing different voices for engaging interactions. It's like having a virtual assistant on steroids, ready to tackle any query you throw its way. From discussing the GSM 8K dataset to accurately identifying objects in a video background, this model proves its mettle in handling diverse tasks with precision and flair.
What sets Quen's model apart is its innovative architecture, featuring a unique positional embedding system for temporal information. The Thinker-Talker setup ensures seamless processing of inputs and generation of speech outputs, making it a standout in the realm of AI models. This model's end-to-end training and compact size of 7 billion parameters underscore its efficiency and effectiveness in delivering top-notch performance.
In a world where AI models are constantly evolving, Quen's Omni model stands out as a beacon of progress and innovation. Its ability to handle various tasks, generate different voices, and provide detailed responses showcases the immense potential of multimodal models. With Quen's model leading the charge, the future of AI looks brighter and more exciting than ever before.

Image copyright Youtube
Image copyright Youtube
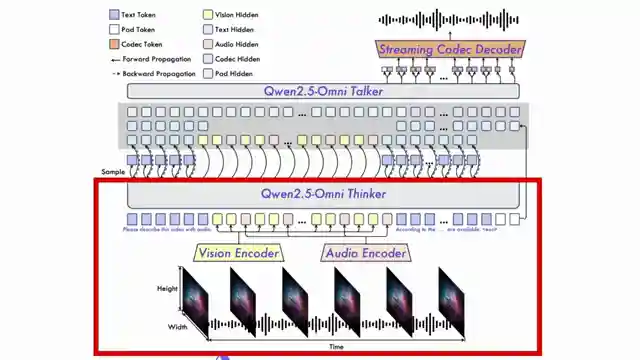
Image copyright Youtube
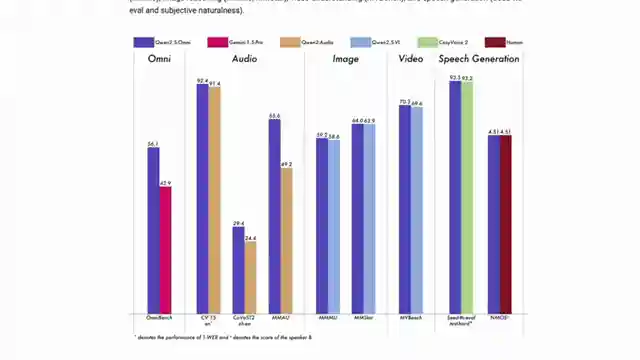
Image copyright Youtube
Watch Qwen 2.5 Omni - Your NEW Open Omni Powerhouse on Youtube
Viewer Reactions for Qwen 2.5 Omni - Your NEW Open Omni Powerhouse
Viewer impressed by channel's content quality
Request for needle in haystack video benchmarks
Interest in experiencing "live" conversation interface like on the website
Inquiry about providing voice samples with different accents
Comparison to other omni models
Questioning the need for human receptionists with advanced chat technology
Curiosity about openwebUI supporting a similar live chat interface
Speculation on the impact on OpenAI's competition
Inquiry about VRAM requirements for running the model
Criticism on the quality of voices and accents, suggesting the need for native English speakers.
Related Articles

Unleashing Gemini CLI: Google's Free AI Coding Tool
Discover the Gemini CLI by Google and the Gemini team. This free tool offers 60 requests per minute and 1,000 requests per day, empowering users with AI-assisted coding capabilities. Explore its features, from grounding prompts in Google Search to using various MCPS for seamless project management.

Nanet's OCR Small: Advanced Features for Specialized Document Processing
Nanet's OCR Small, based on Quen 2.5VL, offers advanced features like equation recognition, signature detection, and table extraction. This model excels in specialized OCR tasks, showcasing superior performance and versatility in document processing.

Revolutionizing Language Processing: Quen's Flexible Text Embeddings
Quen introduces cutting-edge text embeddings on HuggingFace, offering flexibility and customization. Ranging from 6B to 8B in size, these models excel in benchmarks and support instruction-based embeddings and reranking. Accessible for local or cloud use, Quen's models pave the way for efficient and dynamic language processing.

Unleashing Chatterbox TTS: Voice Cloning & Emotion Control Revolution
Discover Resemble AI's Chatterbox TTS model, revolutionizing voice cloning and emotion control with 500M parameters. Easily clone voices, adjust emotion levels, and verify authenticity with watermarks. A versatile and user-friendly tool for personalized audio content creation.