Small Dockling: Precision OCR for Document Understanding

- Authors
- Published on
- Published on
In the realm of OCR models, Small Dockling from Hugging Face and IBM is like a compact sports car in a world of bulky SUVs. With just 256 million parameters, this little powerhouse can zoom through documents with precision, leaving competitors in the dust. While it may not be the biggest on the block, Small Dockling packs a punch by focusing not just on OCR but on the art of document conversion, a feat that sets it apart from the crowd. It claims to outshine rivals by a staggering 27 times, a bold statement that demands attention.
The Small Dockling project is not your run-of-the-mill OCR tool; it's a sophisticated extraction wizard capable of handling a variety of document formats with finesse. By combining a vision encoder and LM model, this OCR marvel delivers not only text recognition but also detailed location data in a sleek "dock tags" format, reminiscent of a high-tech blueprint. Its prowess extends to code recognition, formula extraction, and chart interpretation, making it a versatile contender in the OCR arena.
Available on Hugging Face, Small Dockling invites users to take it for a spin and experience its capabilities firsthand. While it may not be the ultimate OCR champion in every aspect, its compact size and focus on document conversion make it a compelling choice for those seeking tailored solutions. By offering fine-tuning options and script support, Hugging Face ensures that Small Dockling can be customized to excel in specific tasks, setting it apart as a nimble and adaptable tool in the world of OCR technology. Share your Small Dockling adventures in the comments and gear up for a thrilling ride through the realm of document understanding.
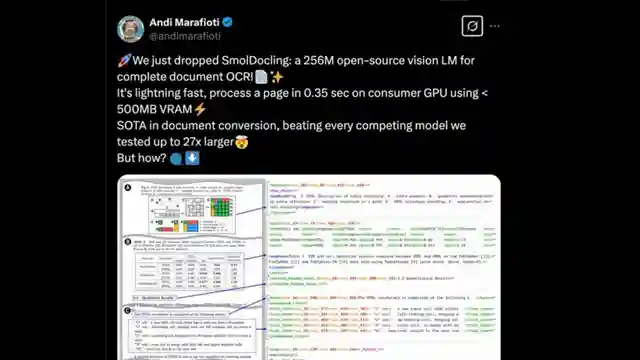
Image copyright Youtube
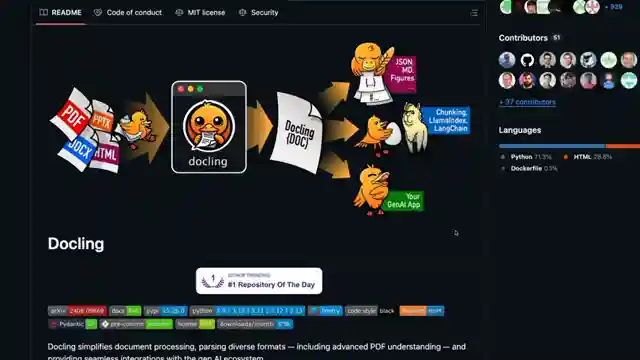
Image copyright Youtube
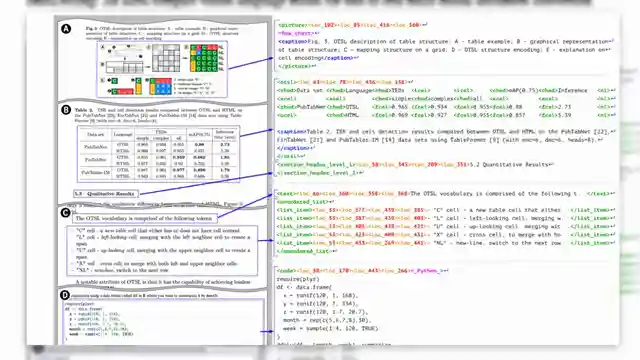
Image copyright Youtube
Image copyright Youtube
Watch SmolDocling - The SmolOCR Solution? on Youtube
Viewer Reactions for SmolDocling - The SmolOCR Solution?
SmolDocling is seen as a replacement for OCR, offering more than just text extraction
Docling is praised for its accuracy and speed compared to other models like Gemini and Mistral
Users are curious about the integration of Tesseract engine and its compatibility with Docling
Some users are interested in using Docling for specific tasks like RAG pipeline and transforming outputs into LaTeX
Questions about the model's performance with different languages, handwriting, and maximum resolution
Comparison requests between SmolDocling and Donut
Interest in using Docling for detecting specific elements like headlines or CTAs in static display ads
Suggestions for fine-tuning the model for specific use cases, such as handling shorthand
Some users express difficulty or dissatisfaction with the results obtained from using Docling
Speculation on the main purpose of the model being to publish a paper about it
Related Articles

Unleashing Gemini CLI: Google's Free AI Coding Tool
Discover the Gemini CLI by Google and the Gemini team. This free tool offers 60 requests per minute and 1,000 requests per day, empowering users with AI-assisted coding capabilities. Explore its features, from grounding prompts in Google Search to using various MCPS for seamless project management.

Nanet's OCR Small: Advanced Features for Specialized Document Processing
Nanet's OCR Small, based on Quen 2.5VL, offers advanced features like equation recognition, signature detection, and table extraction. This model excels in specialized OCR tasks, showcasing superior performance and versatility in document processing.

Revolutionizing Language Processing: Quen's Flexible Text Embeddings
Quen introduces cutting-edge text embeddings on HuggingFace, offering flexibility and customization. Ranging from 6B to 8B in size, these models excel in benchmarks and support instruction-based embeddings and reranking. Accessible for local or cloud use, Quen's models pave the way for efficient and dynamic language processing.

Unleashing Chatterbox TTS: Voice Cloning & Emotion Control Revolution
Discover Resemble AI's Chatterbox TTS model, revolutionizing voice cloning and emotion control with 500M parameters. Easily clone voices, adjust emotion levels, and verify authenticity with watermarks. A versatile and user-friendly tool for personalized audio content creation.