Revolutionizing AI: Meta AI's BLT Model Transforms Large Language Models

- Authors
- Published on
- Published on
In this episode of 1littlecoder, we delve into the revolutionary BLT bite latent transformer model from Meta AI, a game-changer in the world of large language models. Forget tokenization, this model operates at the byte level, offering unparalleled efficiency and performance that rivals the mighty llama 3. With 8 billion parameters, BLT stands tall, proving that bigger doesn't always mean better. It slashes compute requirements by 50%, paving the way for a new era of AI that's leaner, meaner, and more powerful than ever before.
Unlike its token-based counterparts, BLT shuns the traditional vocabulary shackles, opting instead for dynamic patches that unleash a wave of creativity and innovation. This model doesn't play by the rules – it's dynamic, adaptive, and ready to tackle any challenge thrown its way. By allocating compute based on content entropy, BLT ensures that every byte counts, leading to a robust and resilient system that can weather any storm. Say goodbye to sensitivity to noise and hello to a model that's as tough as nails.
But that's not all – BLT isn't just efficient, it's also multilingual and fair. By focusing on bytes rather than tokens, this model breaks down language barriers and levels the playing field for all. And when it comes to scaling, BLT reigns supreme, outperforming traditional models with ease. It's a win-win for the AI world, a leap forward towards the elusive goal of AGI. So buckle up, folks, because the BLT model is here to shake things up and drive us into a future where possibilities are endless and innovation knows no bounds.
Image copyright Youtube
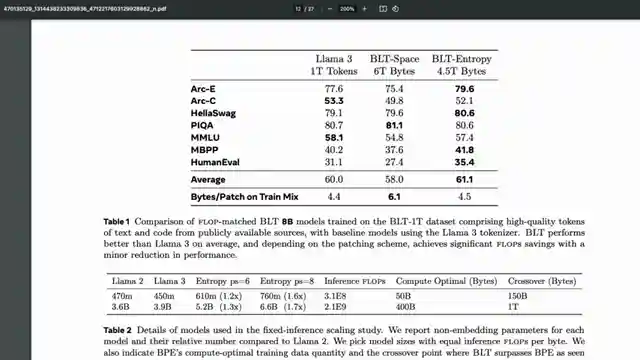
Image copyright Youtube
Image copyright Youtube
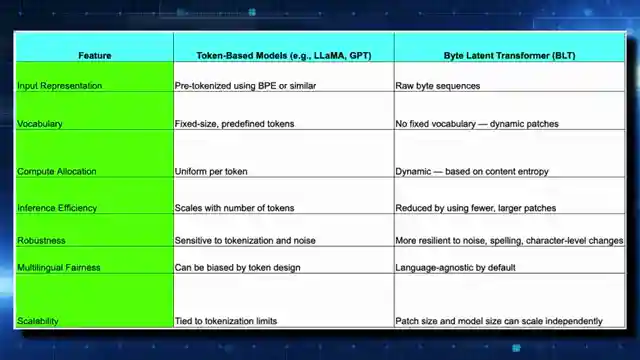
Image copyright Youtube
Watch This is HUGE for LLM Efficiency 💥 End of Tokenization? 💥 on Youtube
Viewer Reactions for This is HUGE for LLM Efficiency 💥 End of Tokenization? 💥
Transformers transitioning from hieroglyphs to using an alphabet
Mention of BPE as a particular inductive bias
Reference to the original paper "Bytes Are All You Need"
Inquiry about the diffusion of LLM models
Concerns about producing multi-modal output without a vocabulary
Discussion on byte-level language models and tokenization
Reference to a vector reasoning paper boosting efficiency
Speculation on the future of byte-level models in AI research institutions
Mention of Google's Byte Latent Transformer and its potential improvements
Potential challenges and limitations of byte-level models compared to tokenization
Related Articles

Revolutionizing Music Creation: Google's Magenta Real Time Model
Discover Magenta, a cutting-edge music generation model from Google deep mind. With 800 million parameters, Magenta offers real-time music creation on Google Collab TPU. Available on Hugging Face, this AI innovation is revolutionizing music production.

Nanits OCRS Model: Free Optical Character Recognition Tool Outshines Competition
Discover Nanits' OCRS model, a powerful optical character recognition tool fine-tuned from Quinn 2.5 VLM. This free model outshines Mistral AI's paid OCR API, excelling in latex equation recognition, image description, signature detection, and watermark extraction. Accessible via Google Collab, it offers seamless conversion of documents to markdown format. Experience the future of OCR technology with Nanits.

Revolutionizing Voice Technology: Chatterbox by Resemble EI
Resemble EI's Chatterbox, a half-billion parameter model licensed under MIT, excels in text-to-speech and voice cloning. Users can adjust parameters like pace and exaggeration for customized output. The model outperforms competitors, making it ideal for diverse voice applications. Subscribe to 1littlecoder for more insights.

Unlock Productivity: Google AI Studio's Branching Feature Revealed
Discover the hidden Google AI studio feature called branching on 1littlecoder. This revolutionary tool allows users to create different conversation timelines, boosting productivity and enabling flexible communication. Branching is a game-changer for saving time and enhancing learning experiences.