Quen's qwq 32b Model: Local Reasoning Powerhouse Outshines Deep seek R1

- Authors
- Published on
- Published on
In this latest release from Quen, the qwq 32b model has arrived to shake up the local reasoning model scene. Learning from its preview version and taking cues from the Deep seek R1, this new model packs a punch. With a focus on efficiency and performance, Quen seems to have hit the nail on the head with this one. While not confirmed if it will be open-source, the model is geared towards production use, setting it apart from the rest.
Comparing the 32b model to the behemoth 671b Deep seek R1, Quen's creation proves that bigger isn't always better. Surpassing the mixed experts model in certain benchmarks, the 32b model showcases its prowess in the realm of reasoning models. Utilizing outcome-based rewards and traditional LLN RL methods, Quen's approach to training the model is both innovative and effective. The focus on math and coding tasks highlights the model's ability to excel in specific domains.
For those keen on putting the qwq 32b model to the test, it's readily available on Hugging Face for a trial run. Be prepared for a RAM-heavy experience, but the results may just be worth it. With the option to try out the Quen 2.5 Max model and compare outputs, users can delve into the world of local reasoning models like never before. In a market saturated with distilled reasoning models, Quen's offering stands out as a top contender, providing a blend of performance and accessibility for enthusiasts and professionals alike.

Image copyright Youtube
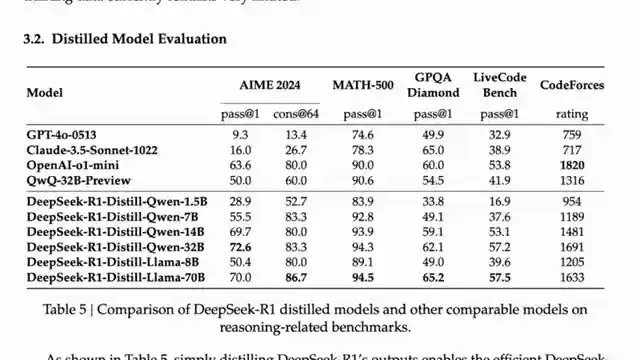
Image copyright Youtube
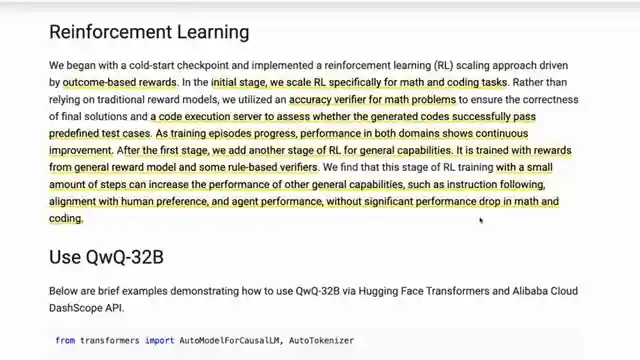
Image copyright Youtube

Image copyright Youtube
Watch Qwen QwQ 32B - The Best Local Reasoning Model? on Youtube
Viewer Reactions for Qwen QwQ 32B - The Best Local Reasoning Model?
Users are impressed with the new release of the model, noting improved formatting, readability, and explanations.
Some users mention the model's large size and token consumption.
There is anticipation for the open-sourcing of the QwQ Max model once it matures.
Comparisons are made to other models like llama 3.3 70b and GPT4o.
Users have tested the model locally and experienced delays in processing but note good output quality.
Suggestions are made for testing the model's browsing capabilities and multi-stage tasks.
A prompt test involving a moral dilemma did not yield correct answers.
Users compare the model to Deepseek in terms of structure with "think" tags.
Related Articles

Unleashing Gemini CLI: Google's Free AI Coding Tool
Discover the Gemini CLI by Google and the Gemini team. This free tool offers 60 requests per minute and 1,000 requests per day, empowering users with AI-assisted coding capabilities. Explore its features, from grounding prompts in Google Search to using various MCPS for seamless project management.

Nanet's OCR Small: Advanced Features for Specialized Document Processing
Nanet's OCR Small, based on Quen 2.5VL, offers advanced features like equation recognition, signature detection, and table extraction. This model excels in specialized OCR tasks, showcasing superior performance and versatility in document processing.

Revolutionizing Language Processing: Quen's Flexible Text Embeddings
Quen introduces cutting-edge text embeddings on HuggingFace, offering flexibility and customization. Ranging from 6B to 8B in size, these models excel in benchmarks and support instruction-based embeddings and reranking. Accessible for local or cloud use, Quen's models pave the way for efficient and dynamic language processing.

Unleashing Chatterbox TTS: Voice Cloning & Emotion Control Revolution
Discover Resemble AI's Chatterbox TTS model, revolutionizing voice cloning and emotion control with 500M parameters. Easily clone voices, adjust emotion levels, and verify authenticity with watermarks. A versatile and user-friendly tool for personalized audio content creation.