Nvidia GTC 2025: Unveiling Llama Neotron Super 49b V1 and Model Advancements

- Authors
- Published on
- Published on
In this latest Nvidia extravaganza at GTC 2025, Jensen H takes the stage to unveil the company's latest data center innovations. What used to be a developer-centric affair has now morphed into a spectacle aimed squarely at investors. The star of the show? Nvidia's reasoning models, promising a surge in tokens for a myriad of tasks. Enter the llama neotron models, building on the llama 3.1 and 3.3 foundations, with the new llama 3.3 neotron super 49b V1 stealing the spotlight. It sounds like a weapon from a sci-fi flick, but it's all about distilled power from the 70b model.
But why is Nvidia hitching its wagon to the llama series instead of blazing its own trail? With ample GPUs and a crack team of researchers, one would think they'd go solo. Instead, they're tinkering with meta ai's llama models, experimenting with post-training techniques and reinforcement learning. The release of the 49b and 8b models, along with a generous post-training dataset, signals Nvidia's foray into democratizing model training. The dataset, boasting millions of samples across various domains, is a goldmine for those venturing into reasoning model development.
The real test comes when users dive into Nvidia's API to put these models through their paces. The ability to toggle detailed thinking on and off adds a layer of intrigue to the experience. While the 49b model shines with its high-quality thinking reminiscent of Deep seek, the 8b model falls short of expectations. Nvidia's move is bold, but questions linger about the 8b model's viability compared to existing alternatives. As the community delves into these models and shares feedback, the debate over optimal model sizes for local versus cloud usage rages on. With links to code and demos provided, the stage is set for enthusiasts to explore Nvidia's latest offerings and push the boundaries of reasoning model capabilities.

Image copyright Youtube
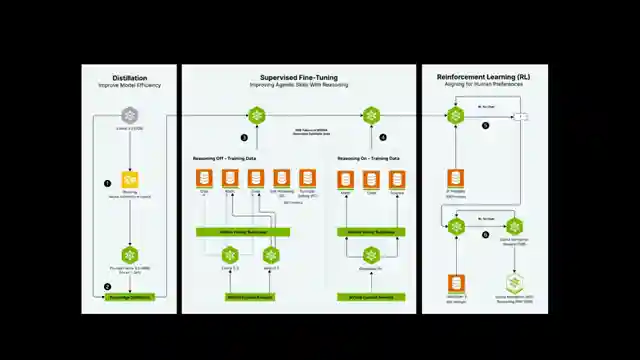
Image copyright Youtube
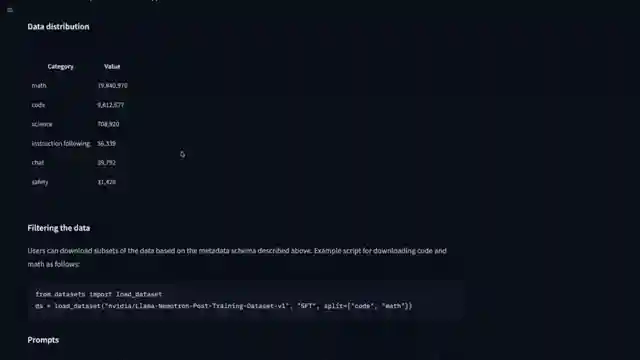
Image copyright Youtube
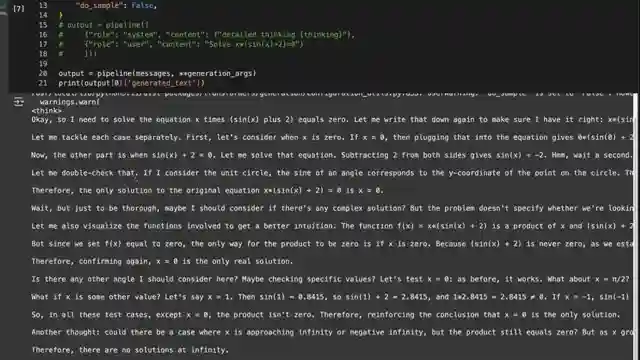
Image copyright Youtube
Watch NVIDIA's New Reasoning Models on Youtube
Viewer Reactions for NVIDIA's New Reasoning Models
Using techniques outside of base model building in Syria makes sense for selling semiconductors
Limited availability of 200 5090s at launch across all US Microcenters
Suggestions for Nvidia to use different base models like qwen instead of llama
Speculation on Nvidia completely changing the original Llama model
Questioning why Nvidia doesn't just inject "think" via chat template
Concerns about Nvidia training its own LLMs from scratch due to legal issues and copyright concerns
Excitement about using the technology on an rx 7900 xtx with ROCm
Criticism of Nvidia for selling excessive energy waste caused by inefficient design applications
Hope for Chinese companies to make Nvidia irrelevant in the AI industry
Related Articles

Unleashing Gemini CLI: Google's Free AI Coding Tool
Discover the Gemini CLI by Google and the Gemini team. This free tool offers 60 requests per minute and 1,000 requests per day, empowering users with AI-assisted coding capabilities. Explore its features, from grounding prompts in Google Search to using various MCPS for seamless project management.

Nanet's OCR Small: Advanced Features for Specialized Document Processing
Nanet's OCR Small, based on Quen 2.5VL, offers advanced features like equation recognition, signature detection, and table extraction. This model excels in specialized OCR tasks, showcasing superior performance and versatility in document processing.

Revolutionizing Language Processing: Quen's Flexible Text Embeddings
Quen introduces cutting-edge text embeddings on HuggingFace, offering flexibility and customization. Ranging from 6B to 8B in size, these models excel in benchmarks and support instruction-based embeddings and reranking. Accessible for local or cloud use, Quen's models pave the way for efficient and dynamic language processing.

Unleashing Chatterbox TTS: Voice Cloning & Emotion Control Revolution
Discover Resemble AI's Chatterbox TTS model, revolutionizing voice cloning and emotion control with 500M parameters. Easily clone voices, adjust emotion levels, and verify authenticity with watermarks. A versatile and user-friendly tool for personalized audio content creation.